Stream laziness in Tabby



This blog focuses on understanding stream laziness in Tabby. You do not need to know this information to use the Tabby, but for those interested, it offers a deeper dive on why and how the Tabby handle its LLM workload.
What is streaming?
Let's begin by setting up a simple example program:
const express = require('express');
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function* llm() {
let i = 1;
while (true) {
console.log(`producing ${i}`);
yield i++;
// Mimic LLM inference latency.
await sleep(1000);
}
}
function server(llm) {
const app = express();
app.get('/', async (req, res) => {
res.writeHead(200, {
'Content-Type': 'application/jsonstream',
'Transfer-Encoding': 'chunked',
});
let value, done;
do {
({ value, done } = await llm.next());
res.write(JSON.stringify(value));
res.write('\n');
} while (!done);
});
app.listen(8080);
}
async function client() {
const resp = await fetch('http://localhost:8080');
// Read values from our stream
const reader = resp.body.pipeThrough(new TextDecoderStream()).getReader();
// We're only reading 3 items this time:
for (let i = 0; i < 3; i++) {
// we know our stream is infinite, so there's no need to check `done`.
const { value } = await reader.read();
console.log(`read ${value}`);
await sleep(10ms);
}
}
server(llm());
client();
In this example, we are creating an async generator to mimic a LLM that produces string tokens. We then create an HTTP endpoint that wraps the generator, as well as a client that reads values from the HTTP stream. It's important to note that our generator logs producing ${i}, and our client logs read ${value}. The LLM inference could take an arbitrary amount of time to complete, simulated by a 1000ms sleep in the generator.
Stream Laziness
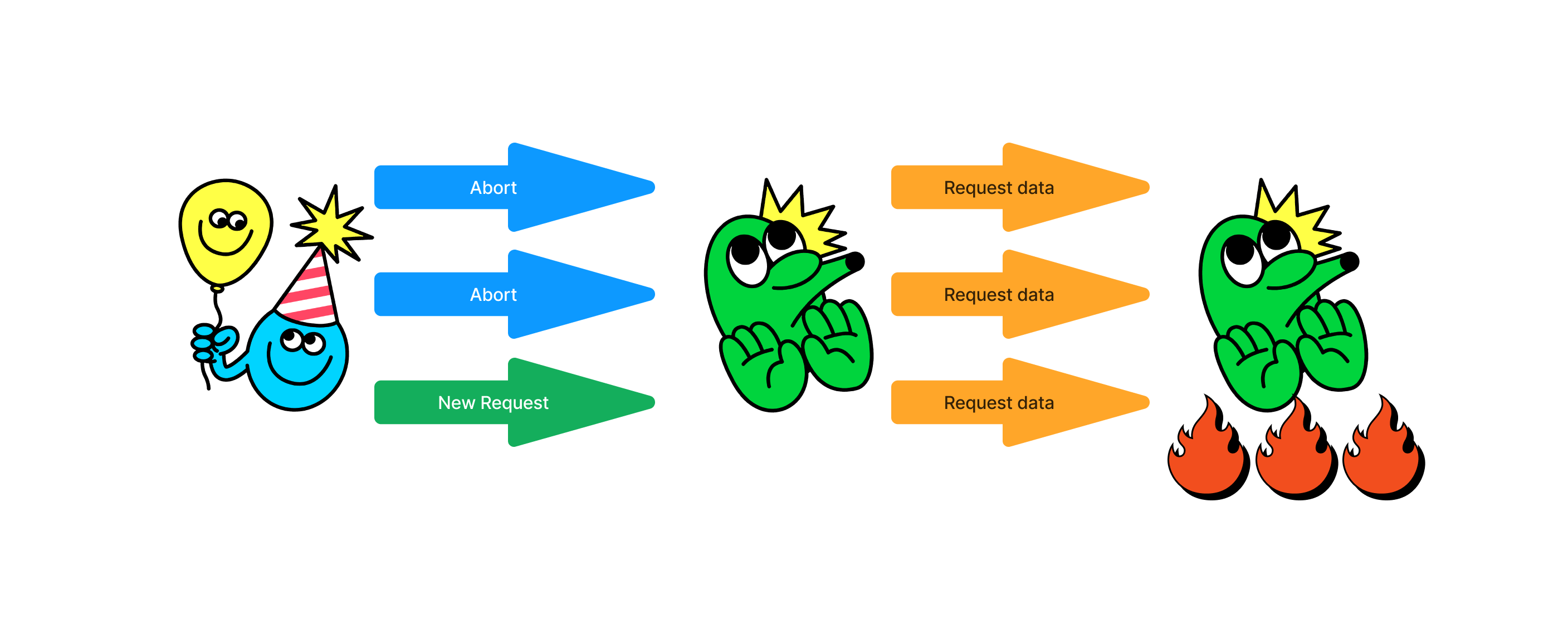
If you were to run this program, you'd notice something interesting. We'll observe the LLM continuing to output producing ${i} even after the client has finished reading three times. This might seem obvious, given that the LLM is generating an infinite stream of integers. However, it represents a problem: our server must maintain an ever-expanding queue of items that have been pushed in but not pulled out.
Moreover, the workload involved in creating the stream is typically both expensive and time-consuming, such as computation workload on the GPU. But what if the client aborts the in-flight request due to a network issue or other intended behaviors?
This is where the concept of stream laziness comes into play. We should perform computations only when the client requests them. If the client no longer needs a response, we should halt production and pause the stream, thereby saving valuable GPU resources.
How to handle cancellation?
The core idea is straightforward: on the server side, we need to listen to the close event and check if the connection is still valid before pulling data from the LLM stream.
app.get('/', async (req, res) => {
...
let canceled;
req.on('close', () => canceled = true);
do {
({ value, done } = await llm.next());
...
} while (!done && !canceled);
});
Implement cancellation for Tabby
In Tabby, effective management of code completion cancellations is crucial for promptly responding to users' inputs while optimizing model usage to enhance performance.
On the client side, whenever we receive a new input from a user, it's essential to abort the previous query and promptly retrieve a new response from the server.
// Demo code in the client side
let controller;
const callServer = (prompt) => {
controller = new AbortController();
const signal = controller.signal;
// 2. calling server API to get the result with the prompt
const response = await fetch("/v1/completions", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({ prompt })
signal
});
}
const onChange = (e) => {
if (controller) controller.abort(); // Abort the previous request
callServer(e.target.value);
};
// 1. Debounce the input 100ms for example
<input onChange={debounce(onChange)} />
By employing streaming and implementing laziness semantics appropriately, all components operate smoothly and efficiently!
That's it
We would love to invite to join our Slack community! Please feel free to reach out to us on Slack - we have channels for discussing all aspects of the product and tech, and everyone is welcome to join the conversation.
Happy hacking 😁💪🏻