Introducing the Coding LLM Leaderboard

In our previous post on Cracking the Coding Evaluation, we shed light on the limitations of relying on HumanEval pass@1 as a code completion benchmark. In response, we've launched the Coding LLMs Leaderboard, embracing Next Line Accuracy as a metric inspired by academic works such as RepoCoder, RepoBench, and CCEval.
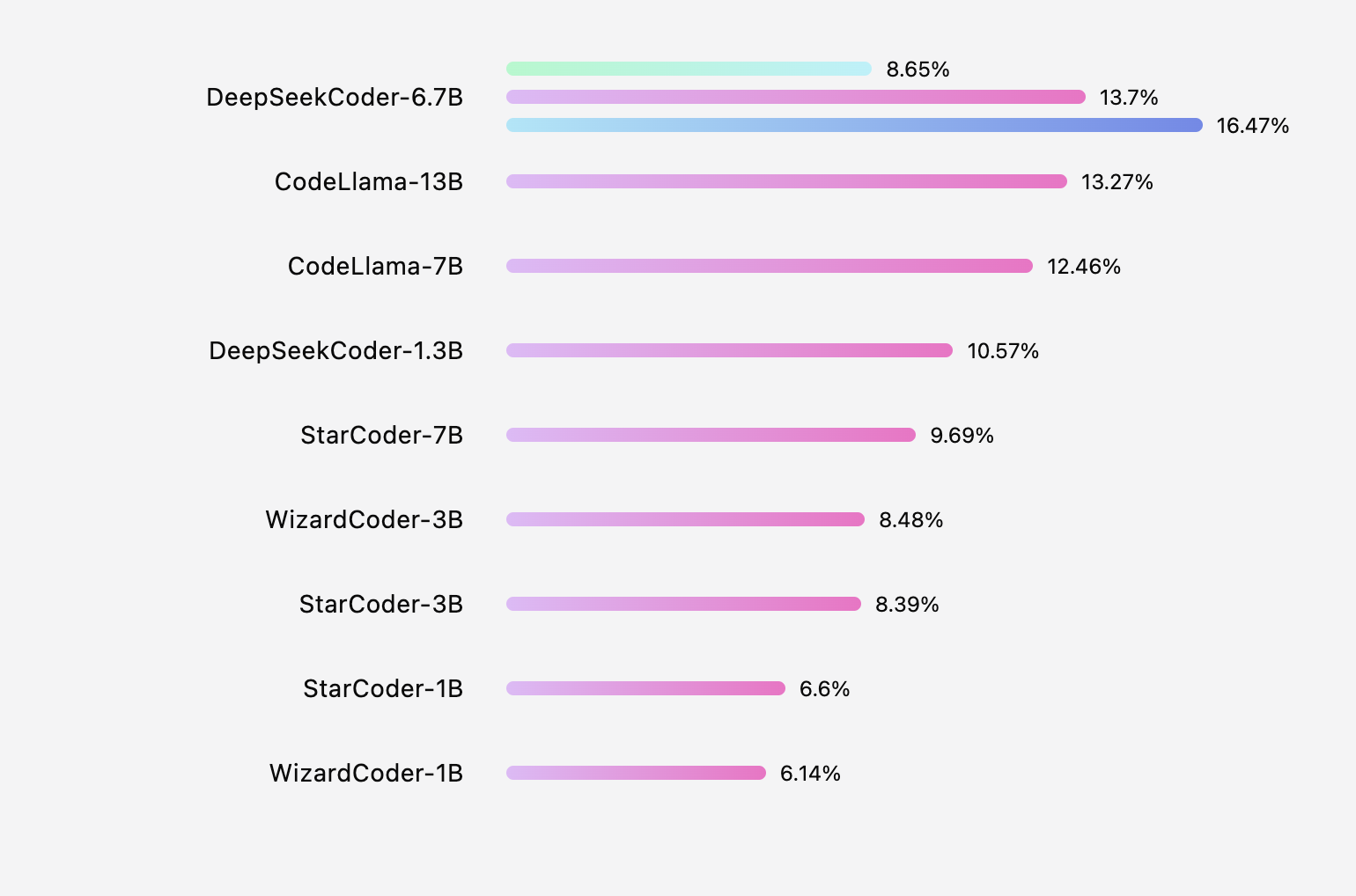
But what exactly is line accuracy? In code completion, model predicts a block of code spanning multiple lines. A naive approach would involve comparing the predicted block with the actual code being committed directly. While this approach might seem ideal, it is often considered "too sparse" as a revealing metric. On the other hand, next-line accuracy serves as a dependable proxy for overall block match accuracy.
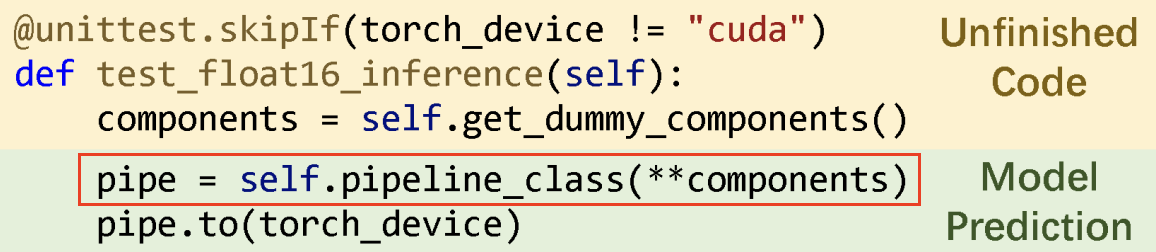
Only content inside red box are used to compared with ground truth to compute accuracy metric
CCEval utilizes the next statement, but based on our observations, it strongly correlates with next line exact match. Therefore, we've opted for next line accuracy due to its ease of implementation across languages, eliminating the need for language-specific Tree Sitter parsers.
For data preparation, our initial release exclusively leverages the dataset from CCEval. This dataset provides well-structured left context, right context, cross-file context with BM25, and oracle information.
At present, evaluation is limited to prefix text + cross-file context. Our future plans involve more in-depth analyses:
- Comparing accuracy in completing a function's argument list.
- Computing accuracy in completing a function's docstring.
We genuinely believe that this leaderboard can assist Tabby's users in navigating the tradeoff between service cost, quality, and other factors. We are committed to enhancing and refining this leaderboard in the future.