Cracking the Coding Evaluation

Tabby offers an open-source alternative solution to GitHub Copilot with easy setup and self-host options. We embrace an open ecosystem to support major open source coding LLMs (e.g. StarCoder, CodeLlama, WizardCoder, etc.), and enable easy integration of proprietary models. In addition, Tabby performs retrieval-augmented code completion to suggest code from your private codebase. We firmly believe in the continuous advancement in open source coding LLMs, yet we need quantitative measurements to guide the direction of product improvement, and help developers decide their model of choice.
Evaluation coding LLMs has also been a hot topic in academics. Many different metrics targeting different coding tasks have been proposed over the past year. At Tabby, we prioritize on metrics that best resemble real-world development workflow, and of course, the metrics should be constructed with non-biased data sources. In this blogpost, we will discuss our thoughts for desired code completion benchmarks, and also review latest academic progress in this area.
Exisiting Paradigms
Existing coding LLM benchmark mostly focus on Pass@k metric - generating k code samples and measuring how often the results successfully pass given unit tests. OpenAI initially introduced this metric in Evaluating Large Language Models Trained on Code in July 2021, along with the release of HumanEval bechmark dataset.
🤖 HumanEval
HumanEval is a hand-crafted dataset, consisting of 164 Python programming problems with unit tests. An example task looks like:
from typing import List
def below_zero(operations: List[int]) -> bool:
"""
You're given a list of deposit and withdrawal operations on a bank account that starts with zero balance. Your task is to detect if at any point the balance of account fallls below zero, and at that point function should return True. Otherwise it should return False.
>>> below_zero([1, 2, 3]) False
>>> below_zero([1, 2, -4, 5]) True
"""
HumanEval was a pioneer research effort, but now suffers from some unfortunate drawbacks:
-
Data is likely contaminated. HumanEval dataset has been around for over two years and it has been discussed and documented widely online. The latest coding LLMs are likely to have included its test data in training data crawling, which would make the evaluation no longer valid.
-
Trivial coding questions that aren't mimicing real engineering setups. HumanEval includes mostly LeetCode's interview-style questions, where they include a single function for LLMs to fill in the body. In a more realistic corporate setup, developers often add code in multiple files in a single PR, and constantly refer to functions implemented in other files. These are indeed more interesting yet challenging tasks for LLMs to perform, but are critical scenarios for AI coding assitants to land in enterprises.
-
Unit tests are too weak. Researchers noticed that test cases in HumanEval tasks (on average 7.7 tests per problem) aren't enough to guarantee the correctness of the generated code (e.g. a wrong implementation could still pass all existing tests), and thus augmented test cases in HumanEval benchmark by 80x in HumanEvalPlus.

- Limited coverage in programming languages. This one is obvious as HumanEval only includes Python code. We ❤️ all programming languages!
🧩 Mostly Basic Programming Problems (MBPP)
MBPP is another popular benchmark for code generation. Researchers from Google introduced it in the paper Program Synthesis with Large Language Models in August 2021, one month after the release of HumanEval. It contains 974 entry-level Python (as the name clearly suggests) programming tasks. An example looks like:
"""
Write a python function to remove first and last occurrence of a given character from the string.
"assert remove_Occ(\"hello\",\"l\") == \"heo\""
"assert remove_Occ(\"abcda\",\"a\") == \"bcd\""
"assert remove_Occ(\"PHP\",\"P\") == \"H\""
"""
Unlike HumanEval, MBPP targets basic tasks commonly encountered by engineers, such as string manipulation, simple arithmetic, and basic data structure operations. However it still faces similar drawbacks as HumanEval mentioned above.
What we are looking for in coding LLM evaluations?
🔬 Scientific and Relevant Setup
The top thing in our mind is metric setup. Like mentioned above, most existing coding LLM evaluations focus on function-level code generation - given a docstring or a function signature at most, the LLM is expected to generate the entire function body.
Here are what we think a trustworthy evaluation setup should cover:
-
Non-trivial code. Definitely no more Leetcode-style coding questions! The ideal evaluation should target projects with substantial engineering complexity. Evidences like lines of code, number of files, or number of contributors could serve as good indicators to estimate the code complexity.
-
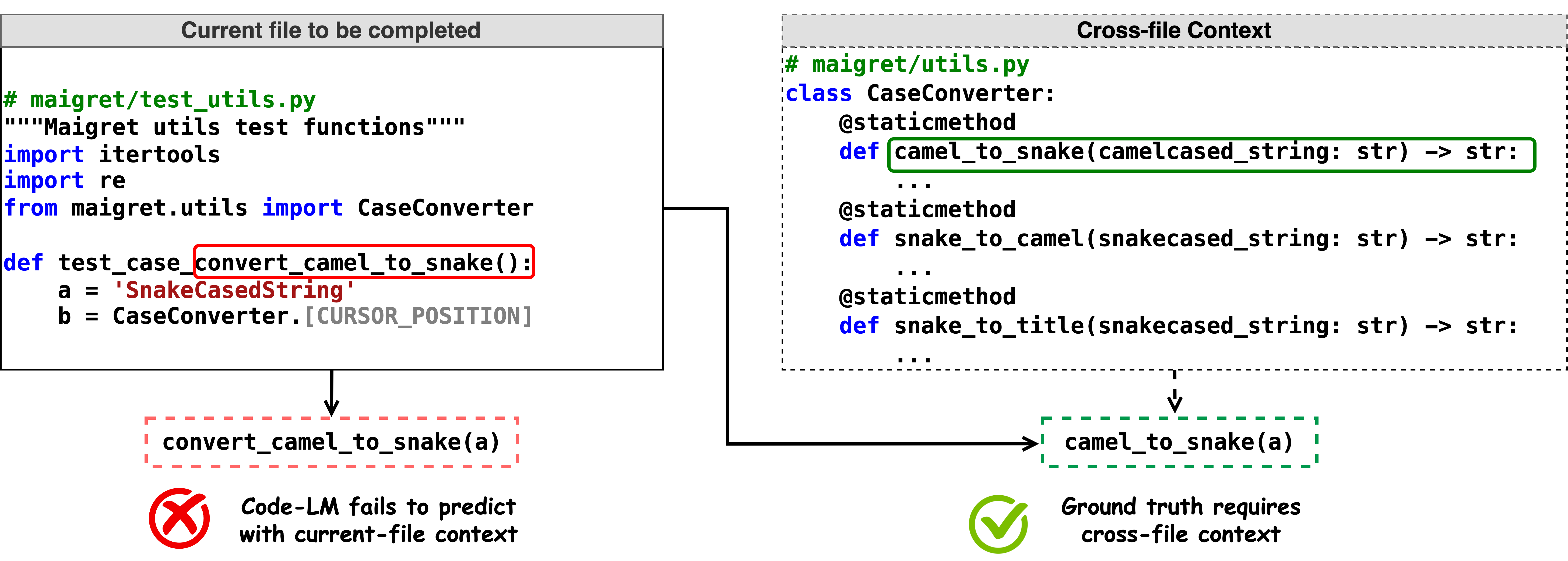
Cross-file references. This is a key factor to differentiate a more reliable and practical evaluation from something that only scratches the surface of the coding world. Engineers do not code in silo, but are greatly encouraged to reuse a function or API implemented in the existing codebase.
-
Code completion. Code completion is the most widely adopted LLM-powered feature in developer tools. Millions of developers worldwide have employed AI code completions in their daily workflow. Tabby provides a low-barrier solution in code completion, and is committed to continue to improve the end-to-end product quality.
⚖️ Ease and Low-Cost to Run
The ease and cost to run evaluations is directly correlated to the number of models we can evaluate, and the frequency we can afford to update the results (in the case of refreshed evaluation date, for example). There are efforts to leverage crowdsourcing to rate the quality of LLM responses (e.g. Glaive arena) which excels at receiving high-quality human feedbacks and provides valuable insights to understand user behaviors. However it's harder to scale crowdsourcing ratings and takes longer to receive results. We are iterating quickly on Tabby, and decided that scalability and ease are critical to us now.
🔍 Data Quality and Inclusion
The data quality is critical to maintain the legitimacy of such evaluation. Here's what's important for evaluation data:
-
Train/Eval Data Split. It's one of the most important concepts in your Machine Learning 101 course. Yet often times it gets so basic that folks neglect the challenges to ensure it in real-world applications over time. For example, HumanEval started as a manually drafted dataset to firmly ensure the data separation. Nevertheless over time, it still faces data contamination issue.
-
Evaluation Quality. HumanEvalPlus mentioned above is a great example for this. Understanding the quality of the evaluation is important for developing a fair sense of the true model performance. We also encourage continuous efforts in improving evaluation quality!💪🏻
-
Data Inclusion / Coverage. In the case of coding, inclusion includes efforts like increasing the support of different programming languages. In practice, choosing the reasonable ratio of each programming language is also tricky yet important.
Highlights of recent research innovations
In this section, we showcase a few recent research work of from the academics toward building reliable and sound evaluations for coding LLMs. Following these papers, we observe a growing emphasize in evaluating coding LLMs with repository-level context, which indeed aligns with what we have been looking for.
🗂️ CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion
CrossCodeEval benchmark specially targets to address the gap that "existing code completion datasets such as HumanEval and MBPP mostly focus on single-file tasks, neglecting the real-world complexity of multi-file software projects". To achieve this goal, CrossCodeEval uses a static-analysis-based method to strictly require cross-file context for accurate code completion. Experiments show that cross-file context improves end-to-end system performance (LLM + code retriever), yet there's still a lot of room to improve.
🧪 RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
RepoBech also recognizes that current benchmarks primarily focus on single-file tasks, which creates a gap in assessing these systems in more complex, real-world, multi-file programming scenarios. Therefore, RepoBench introduces three interconnected evaluation tasks: RepoBench-R (Retrieval), RepoBench-C (Code Completion), and RepoBench-P (Pipeline) to measure the quality of each module and also the end-to-end system.

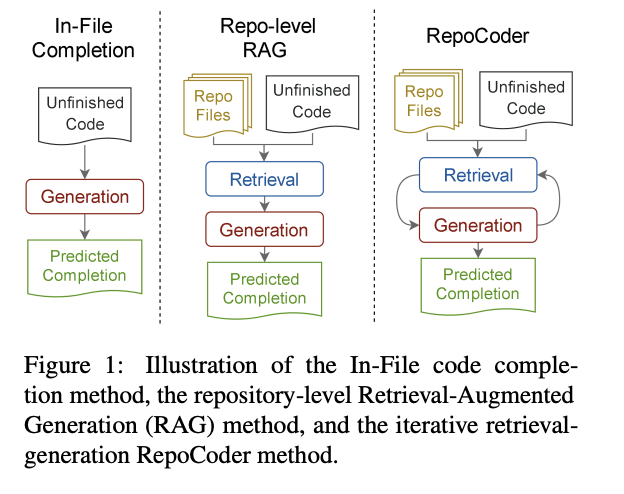
💾 RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
RepoCoder presents an innovative approach of combining similarity-based retriever and LLM prediction into an iterative retrieval-generation pipeline. To demostrate the effectiveness of this method, authors also introduced RepoEval, covering scenarios like line, API invocation, and function body completion from high quality real-world repositories.