Model Configuration
You can configure how Tabby connects with LLM models by editing the ~/.tabby/config.toml file. Tabby incorporates three types of models: Completion, Chat, and Embedding. Each of them can be configured individually.
- Completion Model: The Completion model is designed to provide suggestions for code completion, focusing mainly on the Fill-in-the-Middle (FIM) prompting style.
- Chat Model: The Chat model is adept at producing conversational replies and is broadly compatible with OpenAI's standards.
- Embedding Model: The embedding model generates semantic representations of text data to power Tabby's context-aware features. It indexes the resource code repositories and documentation, then retrieves relevant snippets during chat interactions by embedding user queries. By default, Tabby uses the
Nomic-Embed-Textmodel.
Each model type supports two connection modes:
-
Local Model Connections: Tabby will initiate a subprocess (powered by llama.cpp) and connect to the model via an HTTP API. Supported local models can be found in the Model Registry.
-
Remote Model Connections: Tabby utilizes an HTTP Model Connector to establish a direct connection with the API of model providers like Claude, OpenAI, Ollama, or custom endpoints. More For configuring models through HTTP API, check References / Models HTTP API.
See the following examples of how to configure the model settings in the ~/.tabby/config.toml file:
Local Models
[model.completion.local]
model_id = "StarCoder2-3B"
[model.chat.local]
model_id = "Mistral-7B"
[model.embedding.local]
model_id = "Nomic-Embed-Text"
Remote Models
[model.chat.http]
kind = "openai/chat"
# Please make sure to use a chat model, such as gpt-4o
model_name = "gpt-4o
# For multi-model support
supported_models = ["gpt-3.5-turbo", "gpt-4o", "gpt-4o-mini"]
api_endpoint = "https://api.openai.com/v1"
api_key = "your-api-key"
[model.completion.http]
kind = "ollama/completion"
model_name = "codellama:7b"
api_endpoint = "http://localhost:11434"
prompt_template = "<PRE> {prefix} <SUF>{suffix} <MID>"
[model.embedding.http]
kind = "openai/embedding"
model_name = "text-embedding-3-small"
api_endpoint = "https://api.openai.com/v1"
api_key = "your-api-key"
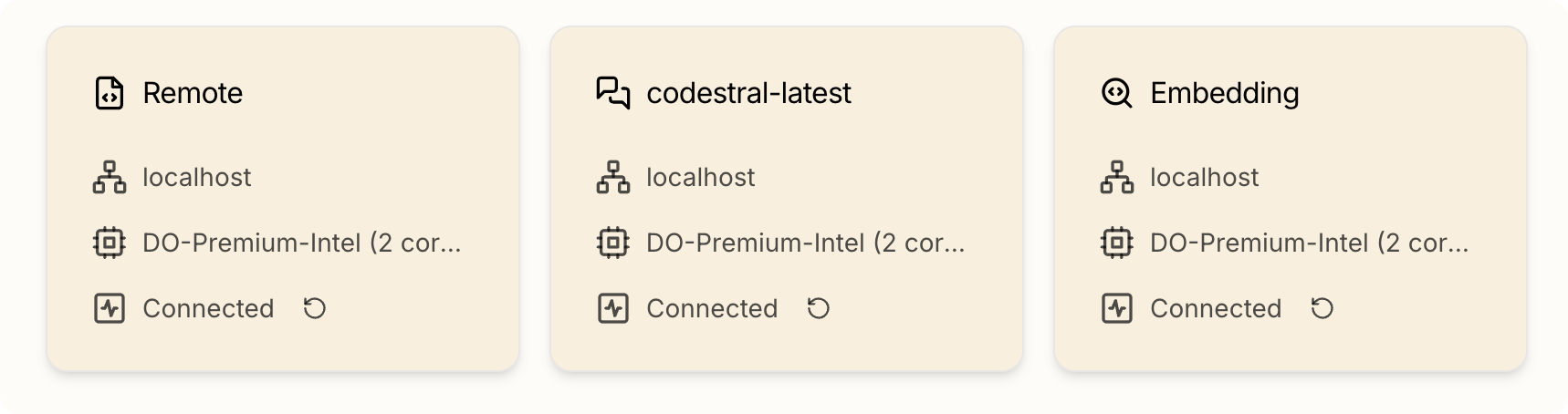
Verifying Model Connection Status
To check whether your configured models are properly connected, navigate to the Information > System page and check individual model cards.
Multi-model Support
When using HTTP connectors for remote chat models, users can dynamically switch between available models in the chat interface by configuring the supported_models parameter.
[model.chat.http]
kind = "openai/chat"
model_name = "gpt-4o"
supported_models = ["gpt-3.5-turbo", "gpt-4o", "gpt-4o-mini"] # For multi-model support
api_endpoint = "https://api.openai.com/v1"
api_key = "your-api-key"
Prompt Templates for HTTP Completion Models
When using HTTP connectors for completion models, some may require configuring a prompt_template to match their expected input format. Different completion models require distinct template structures.
Below are two prompt_template examples. For more examples, refer to Models HTTP API and models.json.
Connecting the completion model with vllm
[model.completion.http]
kind = "vllm/completion"
model_name = "your_model"
api_endpoint = "http://localhost:8000/v1"
api_key = "your-api-key"
# Example prompt template for the CodeLlama model series
prompt_template = "<PRE> {prefix} <SUF>{suffix} <MID>"
Connecting the completion model with llama.cpp
[model.completion.http]
kind = "llama.cpp/completion"
model_name = "your_model"
api_endpoint = "http://localhost:8081" # DO NOT append the `v1` suffix
api_key = "secret-api-key"
# Example prompt template for the Qwen2.5 Coder model series.
prompt_template = "<|fim_prefix|>{prefix}<|fim_suffix|>{suffix}<|fim_middle|>"