Linux
Running Tabby on Linux using Tabby's standalone executable distribution.
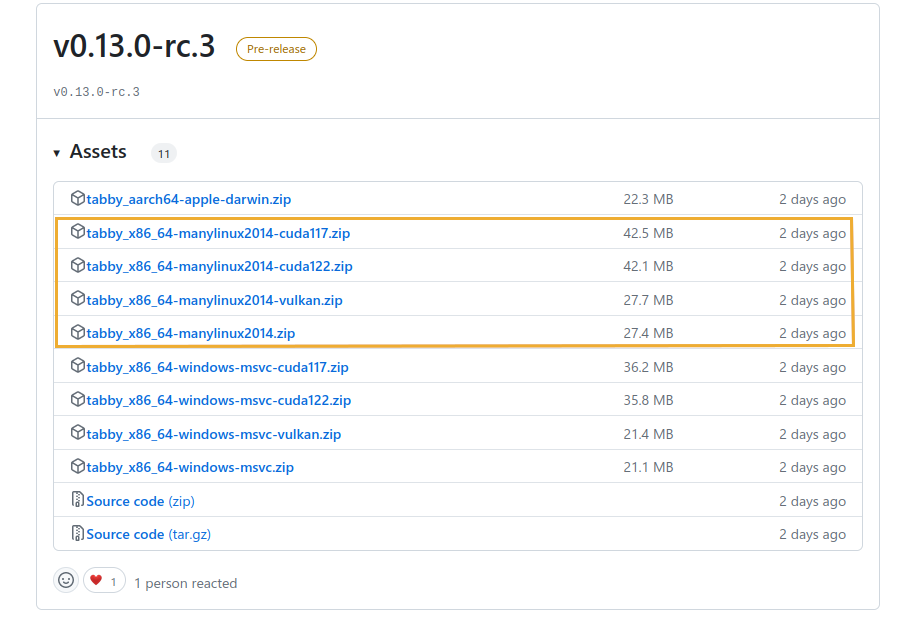
Find the Linux release
- Go to the Tabby release page: https://github.com/TabbyML/tabby/releases
- Click on the Assets dropdown for a specific release to find the manylinux zip files.
Download the release
- If you are using a CPU-only system, download the tabby_x86_64-manylinux2014.zip.
- If you are using a GPU-enabled system, download the tabby_x86_64-manylinux2014-cuda117.zip, In this example, we assume you are using CUDA 11.7.
- If you want to use a non-nvidia GPU, download the tabby_x86_64-manylinux2014-vulkan.zip. See https://tabby.tabbyml.com/blog/2024/05/01/vulkan-support/ for more info.
Tips:
- For the CUDA versions, you will need the nvidia-cuda-toolkit installed for your distribution.
- In ubuntu, this would be
sudo apt install nvidia-cuda-toolkit. - The CUDA Toolkit is available directly from Nvidia: https://developer.nvidia.com/cuda-toolkit
- Ensure that you have CUDA version 11 or higher installed.
- Check your local CUDA version by running the following command in a terminal:
nvcc --version
- In ubuntu, this would be
- For the Vulkan version you'll need the vulkan library. In ubuntu, this would be
sudo apt install libvulkan1.
Katana (optional but recommended)
Tabby utilizes Katana as a crawling backend for the developer docs context provider.
To import and analyze developer docs when llms.txt is unavailable at the specified link, Katana is required.
Please be aware that the minimum Katana version required is 1.1.2.
The simplest way to install Katana is to download a prebuilt binary from the official releases:
curl -L https://github.com/projectdiscovery/katana/releases/download/v1.1.2/katana_1.1.2_linux_amd64.zip -o katana.zip
unzip katana.zip katana
sudo mv katana /usr/bin/
rm katana.zip
This works well for most Linux environments. If you're using a different environment, please refer to the official installation instructions.
Find the Linux executable file
- Unzip the file you downloaded. The
tabbyexecutable will be in a subdirectory of dist. - Change to this subdirectory or relocate
tabbyto a folder of your choice. - Make it executable:
chmod +x tabby llama-server
Run the following command:
# For CPU-only environments
./tabby serve --model StarCoder-1B --chat-model Qwen2-1.5B-Instruct
# For GPU-enabled environments (where DEVICE is cuda or vulkan)
./tabby serve --model StarCoder-1B --chat-model Qwen2-1.5B-Instruct --device $DEVICE
You can choose different models, as shown in the model registry
You should see a success message similar to the one in the screenshot below. After that, you can visit http://localhost:8080 to access your Tabby instance.