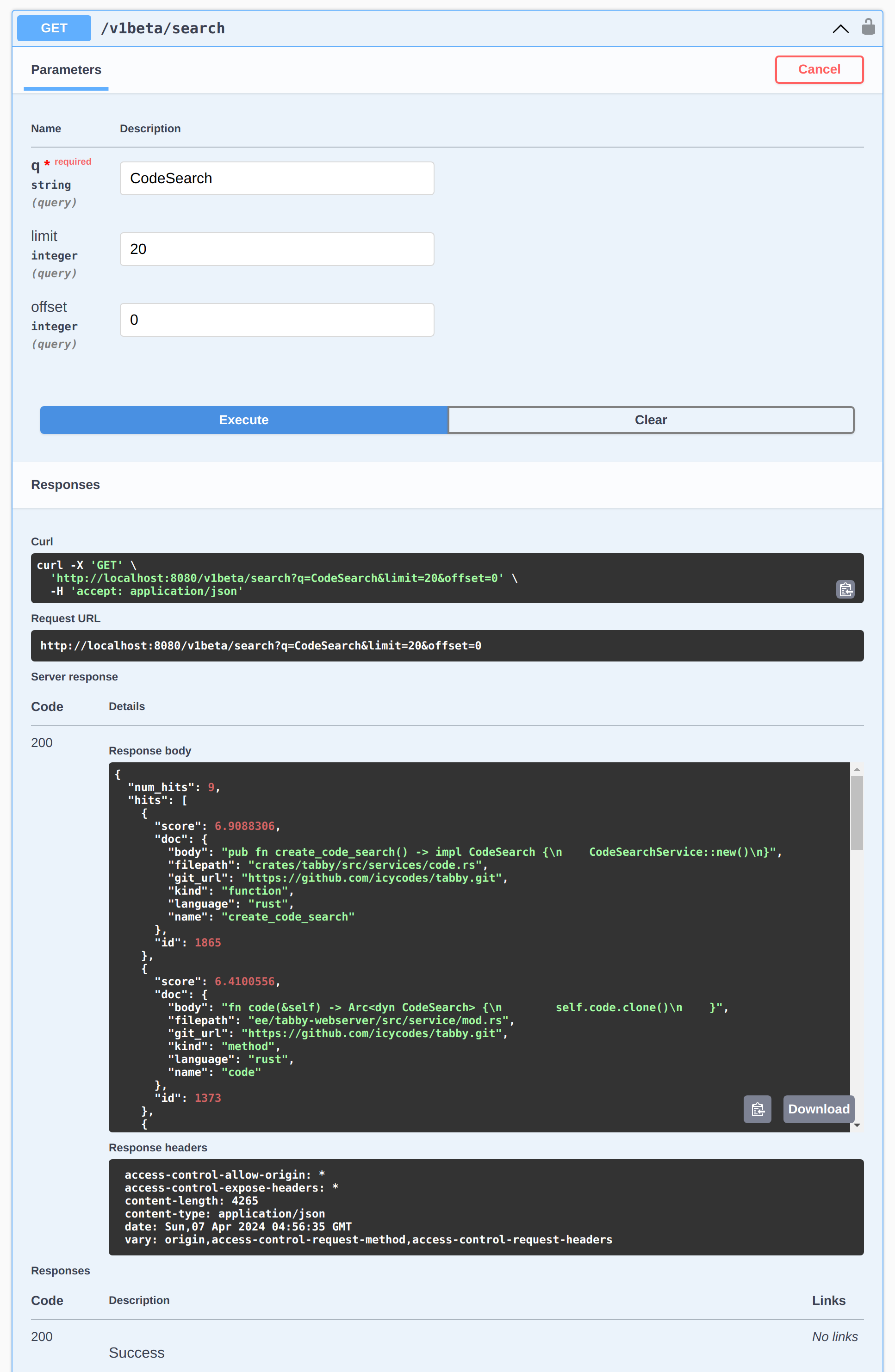
Vulkan Support: LLMs for Everyone

It has long been the case that machine learning models are run on the GPU to improve their performance. The GPU is far more effective at the kinds of computations needed for AI than the CPU, and so GPU compute libraries such as Cuda and ROCm are typically used.
However, requiring the support of these libraries can restrict which graphics cards are compatible, leaving many with older or less popular cards unable to run LLMs efficiently.
Tabby is happy to announce that we now support Vulkan, a graphics library created primarily for games. Its original purpose means that it is designed to work on a very broad range of cards, and leveraging it to host LLMs means that we can now offer GPU acceleration to people whose cards are not supported by Cuda and ROCm.
Vulkan works on basically any GPU, so if you have previously been forced to host local models on your CPU, now is the time to see what Tabby with Vulkan can do for you!
Vulkan Installation
To begin, first make sure that you have Vulkan installed.
For Windows users, Vulkan may be natively supported. Otherwise, the Vulkan SDK can be downloaded at https://vulkan.lunarg.com/sdk/home#windows.
For Linux users, Vulkan can be installed through your package manager:
- Arch Linux: vulkan-icd-loader (universal), and also install vulkan-radeon (for AMD) or vulkan-nouveau (for Nvidia)
- Debian Linux: libvulkan1

Tabby Installation
To start using Tabby with Vulkan, first download one of the pre-built Vulkan binaries for your platform:
- Linux: https://github.com/TabbyML/tabby/releases/download/v0.10.0/tabby_x86_64-manylinux2014-vulkan
- Windows: https://github.com/TabbyML/tabby/releases/download/v0.10.0/tabby_x86_64-windows-msvc-vulkan.exe
Running
Once you've installed the appropriate binary, you can simply run it from the command line:
For Windows, open a command prompt and navigate to the download folder, then run:
tabby_x86_64-windows-msvc-vulkan serve --model StarCoder-1B --device vulkan
For Linux:
./tabby_x86_64-manylinux2014-vulkan serve --model StarCoder-1B --device vulkan
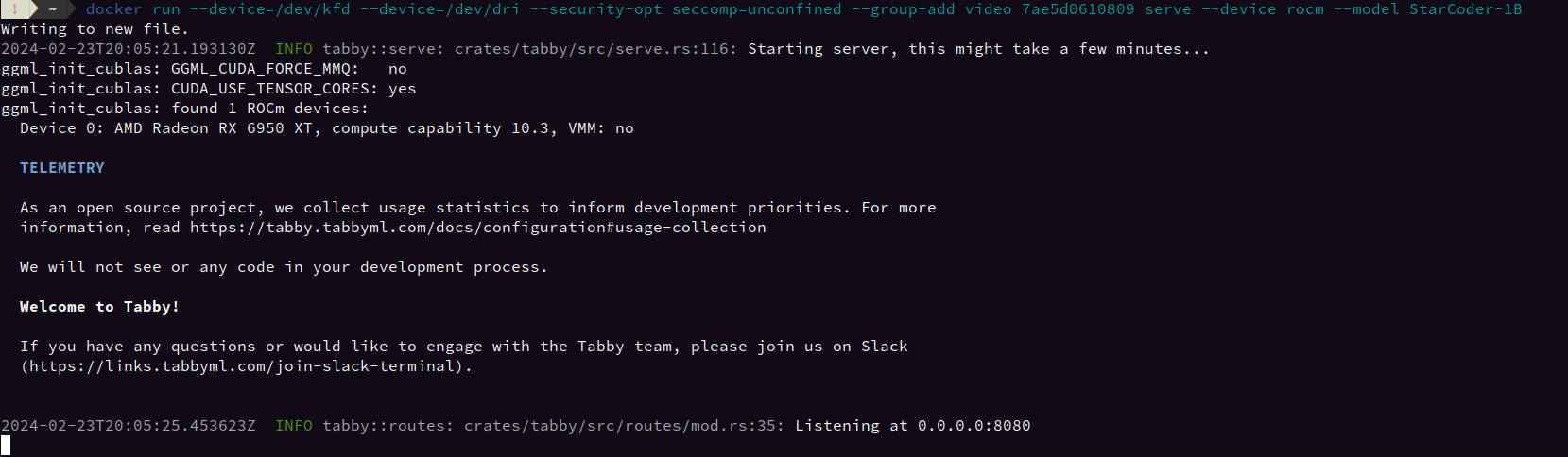
When it starts, you should see a printout indicating that Vulkan has found your card and is working properly:

Now enjoy your speedy completions!